



 Like
Like Share
Share
 Report
ReportOverview
Please make sure to go through the first published blog post of the series as this post will provides you with some essential concepts and semantic about Customer Insights Data (CI-D) Data processing architecture that we’ll re-use through this post.
In this second article about the Azure Data Lake Common Data Model Tables Integration Pattern, we will focus on :
If you've not already done so, please consult the first released article about this pattern to learn more about it.
1.1 Consider a layered lake architecture approach for the pattern implementation
In a customer context, existing Storage Accounts may already be available. Relying on existing Storage Accounts which may serve different purposes (e.g : supporting an existing Data Lake) for CI-D Data ingestion should be avoided.
It is recommended to have a dedicated Storage Account (or, at the very least, a dedicated container) for CI-D as it will allow segregation of duty in terms of security and evolutions.
A typical implementation in a customer context where an existing Data Lake is already in place would rely on the following layered architecture:
Where:
Though CDM can empower many usages outside of the CI-D Realm, this section will focus on describing how to leverage the CDM Metadata system that will describe the Data and Entities in a way they can be understood by Customer Insights Data.
To ensure long-term consistency and ease of maintainability of our Attached Lake, the CDM Folders and associated metadata files need to be properly organized so that the lake does not turn into a swamp.
Customer Insights Data can ingest data files in both CSV, PARQUET and DELTA Tables formats.
Independently of the Data file format, achieving the best data ingestion performance level would require to ensure that the data files for a given table are not split into many small data chunks when it can be avoided:
Currently, CI-D supports the schema of Parquet files produced using the Parquet writer v1.
If you encounter errors like ‘Parquet column cannot be converted in file’ during data ingestion in CI, it is likely that the data to be ingested is following Parquet V2 and the files should be recreated using Parquet V1.
It’s important to ensure that your Lake data tables, folders and columns are provided with “Business Friendly” names, rather than technical names, as you won’t be able to modify those names once the tables are ingested in CI-D.
This will help ensuring that Business Users working in CI-D creating Segments or Measures can easily identify and understand the data which are being made available for them.
You should also pay attention to the following Tables and Columns naming best practices:
1.4 Incremental Data
You must ensure that the incremental folders content (either “Upserts” or “Deletes” folders) are not being modified / updated when CI-D executes an incremental refresh.
The system processes the files in the IncrementalData folder after the specified UTC hour ends. For example, if the system starts processing the incremental refresh on January 21, 2023 at 8:15 AM, all files that are in folder 2023/01/21/07 (representing data files stored from 7 AM to 8 AM) are processed. Any files in folder 2023/01/21/08 (representing the current hour where the files are still being generated) aren't processed until the next run.
When setting up incremental refreshes for a Data Source, a customer will be regularly adding new incremental data sets in its Lake to be ingested into CI-D.
It’s possible to make changes to an existing Table Schema in ADLS which is used for “Azure Data Lake - Common Data Model Tables ” Data Ingestion in CI-D.
Yet, you should be aware of potential impacts that those changes may introduce and anticipate required adaptation in CI-D configuration:
New attributes can be added anywhere in the existing schema of a Data Lake table.
The newly added attributes won’t reflect automatically in CI-D and will require the Table model json file to be updated accordingly to the changes. This must be done by either :
When modifying or deleting attributes, those won’t reflect automatically in CI-D and will require the Table model json file to be updated accordingly to the changes.
This must be done by either :
When working with the Azure Data Lake - Common Data Model Tables Pattern, it’s important to understand that your Lake is becoming the CI-D “Source Lake” which is an integral part of the overall CI-D solution architecture.
You can find some typical and very common issues troubleshooting guidelines through this link of the CI-D product documentation:
Troubleshoot ingestion errors or corrupt data - Dynamics 365 Customer Insights | Microsoft Learn
- The existing Customer Data Lake prepares the Data for different consumption types (i.e. CI-D as a CDP, some BI/DWH/Datamart oriented analytical workload, a custom app …)
- The Customer Insights Data “Source Lake” is an “adapted” layer that will correspond to CI-D consumption needs
- Each arrow represents an ELT pipeline (e.g. ADF, Synapse pipeline …Etc) that brings, transform, filter ..etc the data from one layer to the next.
- The red arrow corresponds to the ELT pipeline that will be managed by the CDP team and that will need to be evolved if the “curated” layer managed by the data lake team changes over time. This is part of Application Lifecycle Management best practices to have this kind of decoupling and to have an agreement between data lake team and CDP team on release cycles, test environments, etc. to ensure no regression will happen on downstream workloads needing that data
The CI-D “adapted” layer (Customer Insights Data “Source Lake”) must be considered an integral part of the CI-D architecture even if it’s technically outside the CI-D platform itself.
1.2 Working with CDM Folders
Though CDM can empower many usages outside of the CI-D Realm, this section will focus on describing how to leverage the CDM Metadata system that will describe the Data and Entities in a way they can be understood by Customer Insights Data.
When leveraging the Azure Data Lake - Common Data Model Tables pattern, customers have the choice to either:
- Automatically generates from CI-D User Interface the CDM Manifest file for your data source and auto-generate the tables attributes schema to also automatically generate the tables CDM metadata file
- Use an already existing CDM structure where Manifest and Tables Metadata files have been produced by the customer
The below guidance refers to the second option where a customer would decide to fully manage its Lake Folders CDM structure and file and metadata files.
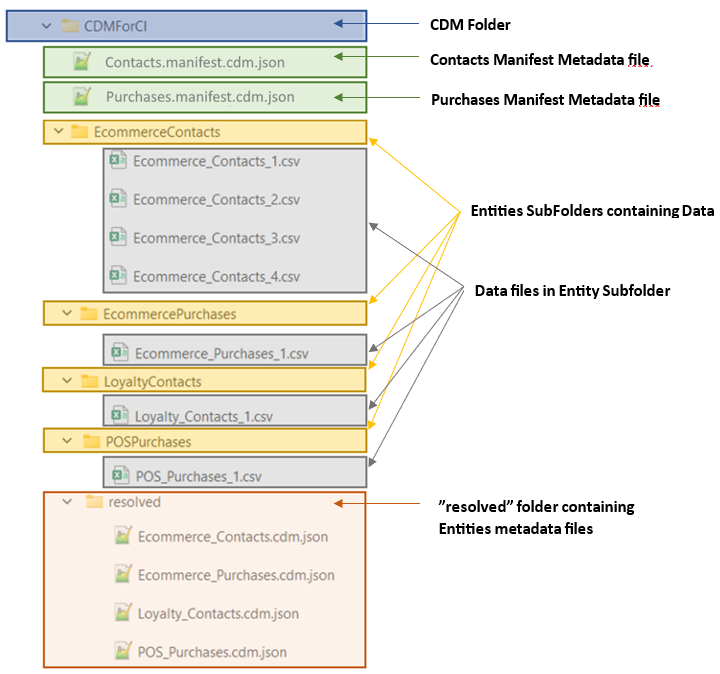
1.2.1 Folders organization
To ensure long-term consistency and ease of maintainability of our Attached Lake, the CDM Folders and associated metadata files need to be properly organized so that the lake does not turn into a swamp.
Before moving forward, you should be familiar with the expected content of CDM folders.
Inside the Customer Insights Data Lake, you should have:
- one subfolder per entity : This subfolder will host the Entity data files.
- one subfolder named “resolved” : By convention this is where all Entities definition file (typically [entity].cdm.json) will reside.
- one manifest file for each Data Source to be ingested in CI-D : each manifest will reference all single entities of the Data Source (typically [DataSource].manifest.cdm.json)
- one subfolder per entity : This subfolder will host the Entity data files.
- one subfolder named “resolved” : By convention this is where all Entities definition file (typically [entity].cdm.json) will reside.
- one manifest file for each Data Source to be ingested in CI-D : each manifest will reference all single entities of the Data Source (typically [DataSource].manifest.cdm.json)
As an example, let’s assume we have the following Entities that have been sinked into an ADLSGen2 storage:
- EcommerceContacts and LoyaltyContacts that will contribute to the Customer Profile unification in CI
- EcommercePurchases and POSPurchases that will contribute to the CI Unified Activities
As a best practice, Contacts related Entities and Transactions related entities should be ingested through separated data sources to optimize the CI-D System Refresh performances.
All entities Data files are provided in CSV with comma delimiter.
The Customer Insights Data Lake filesystem structure should read the following:
1.3 Lake Data Files considerations
1.3.1 Data Files format
Customer Insights Data can ingest data files in both CSV, PARQUET and DELTA Tables formats.
The Azure Data Lake - Common Data Model Tables pattern supports CSV and PARQUET formats but not DELTA Tables. Parquet format is the preferred option when working with this pattern.
Parquet provides higher data compression, leading to reduced storage costs, and an efficient Columnar storage.
In addition, when using CSV files, CI-D will first require to transform the CSV files to a parquet format that will be stored in CI-D Storage Lake. Bringing CSV files format in your lake will thus induce a data duplication step.
| Microsoft recommends the Delta Lake format to obtain the best performance and results for working with large data sets. Customer Insights - Data provides a connector that is optimized for Delta Lake formatted data. |
1.3.2 Data Files size
Independently of the Data file format, achieving the best data ingestion performance level would require to ensure that the data files for a given table are not split into many small data chunks when it can be avoided:
- Each data file should target an ideal size of 1 GB and a maximum of 2 GB
- A single data file folder should not have more than 1000 files
- Typically, the functional key could be based on Time when it comes to activities records such as Ecommerce Purchases or POS Purchases. Those records could be grouped by transaction date on Weeks, Months, Quarters, Semesters or Years
- Identifying the best time grouping will require experimenting with the customer data and see how close we come to the ideal 1GB data file. For one customer it may be month, for another it may be year.
- Even though you may not achieve the ideal 1 GB size, you must focus on defining a records grouping definition that will be consistent from a functional standpoint.
1.3.3 Parquet Data files considerations
Currently, CI-D supports the schema of Parquet files produced using the Parquet writer v1.
If you encounter errors like ‘Parquet column cannot be converted in file’ during data ingestion in CI, it is likely that the data to be ingested is following Parquet V2 and the files should be recreated using Parquet V1.
Please note that if your file size (‘Row Group’) exceeds 128 MB, then you might not be able to see the data preview from CI entities tab. But rest assured, the ingestion works in the background.
Date should be changed to Datetime and follow the ISO 8601 Standard : Date and Time Formats (w3.org)
Date should be changed to Datetime and follow the ISO 8601 Standard : Date and Time Formats (w3.org)
When working with TimeStamps, ensure that your Data is stored in an INT64 Parquet Primitive type instead of INT96 (deprecated). All the datetime fields in an entity should be in the same format
Please also note that TimeStamps with nanosecond precision are not supported since the nanosecond support was introduced with Parquet V2
BSON Data type is not supported
1.3.4 Lake Data tables, folders and columns naming
It’s important to ensure that your Lake data tables, folders and columns are provided with “Business Friendly” names, rather than technical names, as you won’t be able to modify those names once the tables are ingested in CI-D.
This will help ensuring that Business Users working in CI-D creating Segments or Measures can easily identify and understand the data which are being made available for them.
You should also pay attention to the following Tables and Columns naming best practices:
- Do not use spaces in columns, folders or Table name. You may consider replacing spaces by “_”
- Do not use specific characters (such as “-“, “!”, “&” etc) in Columns, Folders or Tables name. You can though use the “_” character.
- Do not use columns with empty names
- Avoid using the “_” character as the leading character for a column name (example: “_id”) or a table Name. Please use a prefix before the “_” (example : MyEntityname_id for a column name)
- Do not use “CustomerId” as a column Name. “CustomerId” is a reserved name for Customer Insights Data.
- The following keywords are reserved and should not be used as table name:
- IncrementalData
- Upserts
- Deletes
1.4 Incremental Data
The Azure Data Lake - Common Data Model Tables pattern supports leveraging incremental data sets that are brought to your lake.
Please refer to the CI-D public documentation to learn more about Incremental ingestion pre-requisites and implementation.
1.4.1 Avoid adding / modifying Incremental Data Sets while executing a CI-D System refresh
You must ensure that the incremental folders content (either “Upserts” or “Deletes” folders) are not being modified / updated when CI-D executes an incremental refresh.
Typically, if you launch a CI-D system refresh at 8 AM UTC, all your csv or parquet data in the “7” incremental folder should be ready for ingestion and not undergoing some data updates. In the same manner, no new csv /parquet data file should be added in this folder.
1.4.2 Understand how tables records are updated in CI-D through incremental refreshes
The system processes the files in the IncrementalData folder after the specified UTC hour ends. For example, if the system starts processing the incremental refresh on January 21, 2023 at 8:15 AM, all files that are in folder 2023/01/21/07 (representing data files stored from 7 AM to 8 AM) are processed. Any files in folder 2023/01/21/08 (representing the current hour where the files are still being generated) aren't processed until the next run.
If there are two records for a primary key, an upsert and delete, Customer Insights - Data uses the record with the latest modified date. For example, if the delete timestamp is 2023-01-21T08:00:00 and the upsert timestamp is 2023-01-21T08:30:00, it uses the upsert record. If the deletion occurred after the upsert, the system assumes the record is deleted.
1.4.3 Plan for regular maintenances of your Lake Data
When setting up incremental refreshes for a Data Source, a customer will be regularly adding new incremental data sets in its Lake to be ingested into CI-D.
The amount of produced incremental data files can quickly grow in the lake, typically if many data partition files are brought on an hourly basis, which can lead to lake maintainability concerns and can also lead to adverse impacts on CI-D ingestion duration for an incremental Data Source.
To avoid the previous concerns, the best practice is to ensure that you’ll regularly re-generate new full data files for the table (meaning : a full data set that will encompass all previous incremental changes up to the day it is produced) and remove the previously created incremental data files from the lake since they’re not needed anymore.
Once a full data set is re-generated, and previous incremental data files are deleted from the lake, you’ll have to manually perform a one-time full refresh of your data source in the CI-D User Interface.
To perform a one-time full refresh, please refer to this article of our public documentation.
We advise to plan this maintenance task at least twice a year and even more frequently (quarterly basis) if a table incremental folder would contain over 2000 data partitions files .
1.5 Handling tables schema changes
It’s possible to make changes to an existing Table Schema in ADLS which is used for “Azure Data Lake - Common Data Model Tables ” Data Ingestion in CI-D.
Yet, you should be aware of potential impacts that those changes may introduce and anticipate required adaptation in CI-D configuration:
1.5.1 Adding New Attributes in a Table Schema
New attributes can be added anywhere in the existing schema of a Data Lake table.
The newly added attributes won’t reflect automatically in CI-D and will require the Table model json file to be updated accordingly to the changes. This must be done by either :
- manually or programmatically update the table.cdm.json file to add the new attributes
- or from CI-D User Interface by auto-generating the schema when editing the CI-D Data Source.
Finally, the modified Data Source has to be ingested in CI-D.
Once those new attributes are ingested, you can then perform the CI-D additional configurations, if required, related to these attributes.
- For example: adding a new attribute to the Unified Customer Fields or Activity Semantic fields, creating a new matching rule etc.
When working on an Incremental Table, you’ll have to regenerate all Table data files (full + incrementals) so that each of the Data Files is exposing the new attributes (even if it’s with null values).
Finally you’ll ask CI-D to re-ingest all updated data files (full files + incremental files) as to obtain a consistent table in CI-D.
1.5.2 Changes of already ingested Attributes (i.e: attribute renaming, Data type change…) or removing attributes
When modifying or deleting attributes, those won’t reflect automatically in CI-D and will require the Table model json file to be updated accordingly to the changes.
This must be done by either :
- manually or programmatically update the table.cdm.json file to add the new attributes
- or from CI-D User Interface by auto-generating the schema when editing the Data Source.
Finally, the modified Data Source has to be ingested in CI-D.
You should be very careful about downstream dependencies which may be associated with an attribute change or deletion:
- If the modified / deleted attribute is used in an existing CI process (Customer or Activity unification, measure calculation, segment rule, relationship, enrichment, OOB AI models etc.) then the CI-D processes based on this changed / deleted attribute will most likely fails on processing
- You’ll then have to change / rebuild the configurations that were dependent on the modified / deleted attribute
- As a best practice, we strongly recommend that when planning for potential changes, a first impact analysis is done on CI-D Configuration to anticipate required configuration changes so that changes are being dealt proactively and in a coordinated manner as to prevent CI-D processes failure and unavailability of critical CI-D Data (Unified Customer Profiles, Segment members …).
- If the modified / deleted attribute is not used in an existing CI-D process, this should not have impact on the existing CI Configuration.
1.6 Carefully plan your Lake Data updates for the next CI-D System refresh
When working with the Azure Data Lake - Common Data Model Tables Pattern, it’s important to understand that your Lake is becoming the CI-D “Source Lake” which is an integral part of the overall CI-D solution architecture.
In this pattern, your Lake data is leveraged “in place” by CI-D to perform its processing activities which induces that your lake data must stay consistent for Business Users operation on the CI-D platform.
To exemplify:
Let’s assume you’ve an “Ecommerce_Orders” table in your lake that you’ve ingested in CI-D. In your lake, this table have a dozen of Parquet Data Partition files and you’re regenerating a daily full data set for this table.
When ingesting this table in CI-D, either through a scheduled system refresh or by manually triggering the table ingestion, CI-D will check all parquet data partition files which are made available from the lake and keep those parquet files name and path for later usage.
Now a Business user builds a new segment in CI-D and use some information from the “Ecommerce_Orders” table to build one rule of the segment.
The Business User saves and run this new segment.
CI-D will then starts processing this segment and will look at the data of the “Ecommerce_Orders” table in your lake by reading the Parquet Data partitions files which were referenced during the last table ingestion.
Now, let’s imagine that you’ve removed the previously ingested parquet files from the lake and replaced them by new ones to reflect the latest update in your Table Data.
Those new parquet files will be unknown to CI-D until the CI-D ingestion process takes place again for this Data Source table.
If the Lake data files changes for “Ecommerce_Orders” happen during Business Hour and the table is not yet ingested again in CI-D, then the segment newly created by the business user will likely fail on processing as CI-D will try to reach to parquet data partition files which are not existing anymore in your lake.
To avoid this, you must ensure that your Lake Data files update will happen after Business hours and before the next system refresh will take place.
If your use cases require some data sources / tables to be updated and being refreshed during business hours then you should consider using incremental ingestion for those data sources / tables as, in this case, previously read parquet data partition files are never changed or deleted from your lake.
You can find some typical and very common issues troubleshooting guidelines through this link of the CI-D product documentation:
Troubleshoot ingestion errors or corrupt data - Dynamics 365 Customer Insights | Microsoft Learn
*This post is locked for comments